Bug #4502
closedTCP reassembly memuse approaching memcap value results in TCP detection being stopped
Description
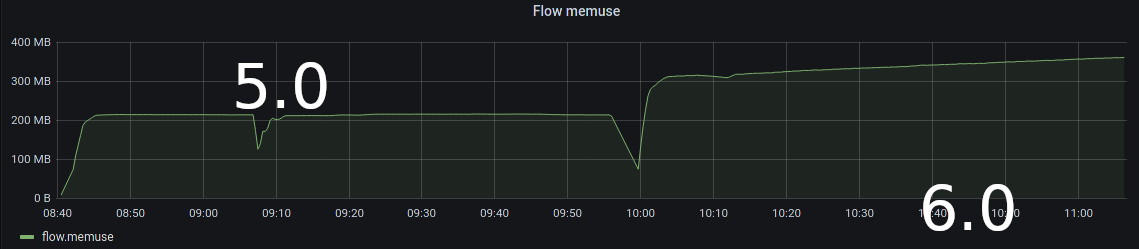
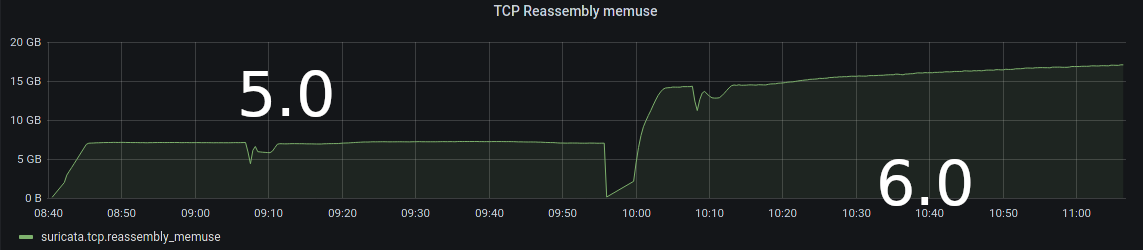
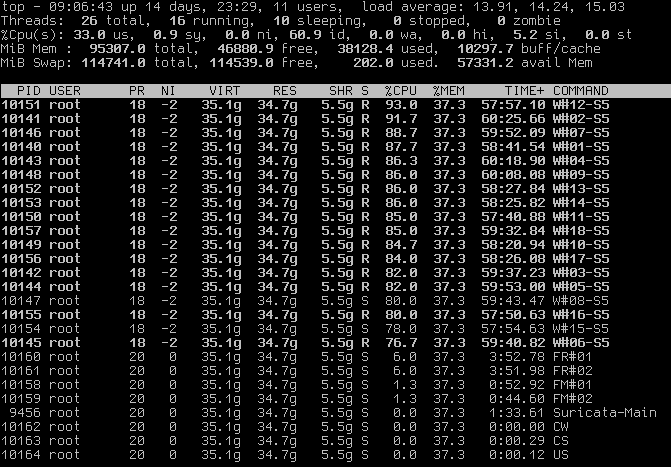
We discovered on the majority of 6.0 deployments have an increase in overall memory usage but especially for tcp reassembly memusage we saw an increase that results with the memuse hitting the memcap (but not .memcap entry in stats.log) and at that point nearly the whole tcp app-layer detection stopped.
We see on all of those deployments some amount of tcp.reassambly_gaps and after the breakpoint where tcp reassembly memuse hits the memcap border those gaps increase much more and now tcp.insert_data_normal_fail starts to occur as well. As you can see in the Grafana output there are some correlations:
- tcp reassembly memuse hitting the limit after less then 24hours with a 8Gbit/s traffic ingest (done via t-rex)
- tcp insert fail rise as soon as the limit is hit
- tcp gaps make a jump as well
- tcp app layer totally gone, only udp (dns) still inspected
- stable values of traffic, load, no drops, flows/min
The most interesting thing is that we can't reproduce it with 5.0.3 while everything else is the same (we only changed the config to not use the new app layer parsers that are only in 6.0).
(In general the overall memory usage with 5.0.3 is much smaller compared to 6.0.2)
In 5.0.3 the tcp memuse as well as flow memuse settle at one plateau which makes much more sense compared to the stable t-rex traffic ingest.
Some system Details:
Debian Buster with 5.10 Backports kernel.
Capture on X710 10GE SFP+ NICS with AF_PACKETv3 although there was no diff with using cluster_qm + RSS setting or just cluster_flow with 1 Queue.
Current workaround is a daily restart of Suricata for 6.0.2 and might be necessary to rollback to 5.0.3.
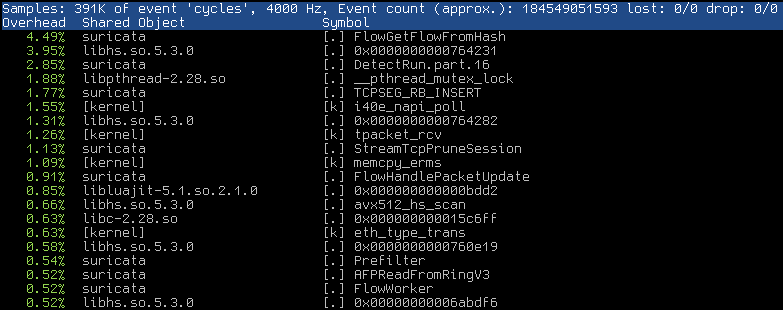
Any hints where we should look on the code side will help, nevertheless we will also check the git log if we can spot something for that regression.
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}